
My girlfriend constantly beats me in WordHunt. It’s borderline insane. She is way better than me at finding words, but also just way way faster at trying possibilities. Call it GenZ birthright.
This string of losses plus the fact that I recently got asked about a trie structure in an interview recently, led me to build out a solver for the popular game WordHunt.
Motivation
The motivation was to finally get a win in WordHunt and to explore some Python libraries that I have been wanting to use.
Computer Vision was my favorite class in college taught by Matt Zucker. This was use very small elements of that, and pyautogui to control your phone through your Mac and play through iPhone Mirroring. As is growing typical of software now, it also uses a small OpenAI LLM call with structured outputs and an image upload to help with detecting our grid. I’ll talk more about that later.
Driving Motivation
So how did we do? Pretty well 😏
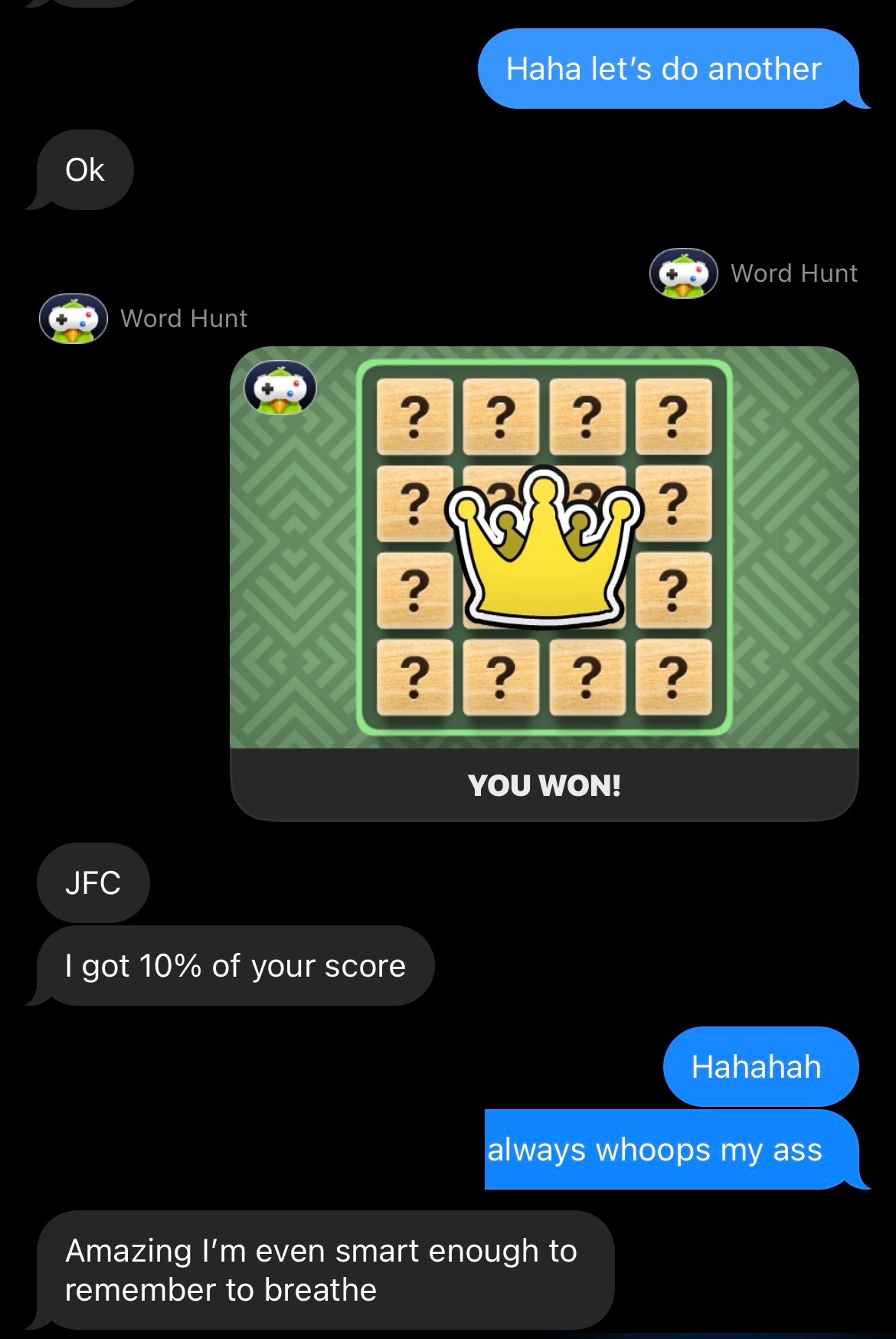
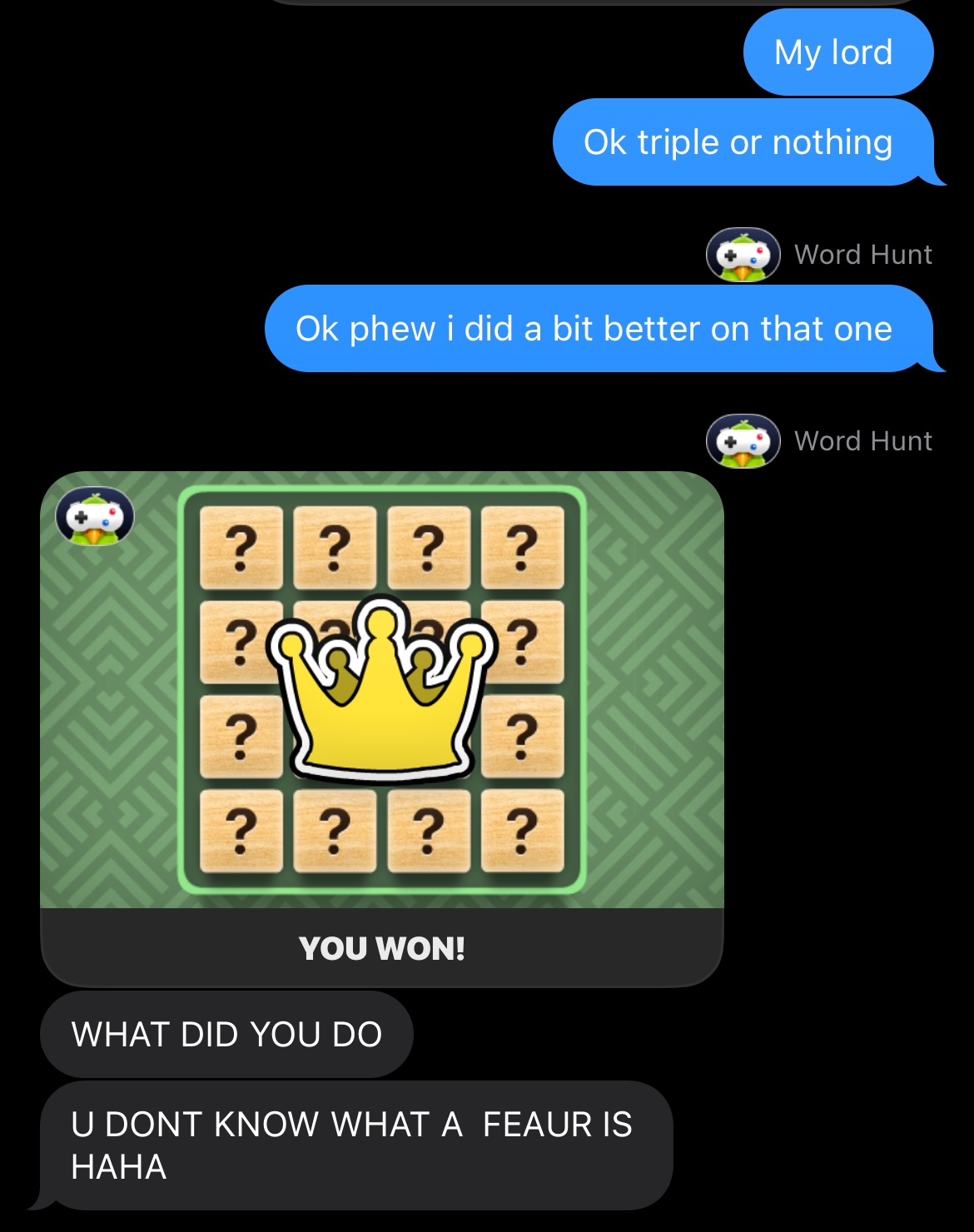
Here’s an actual demo of the solver operating. Note, the fallback to OpenAI if we’re unsure about a various cell (or have miscomputed a grid).
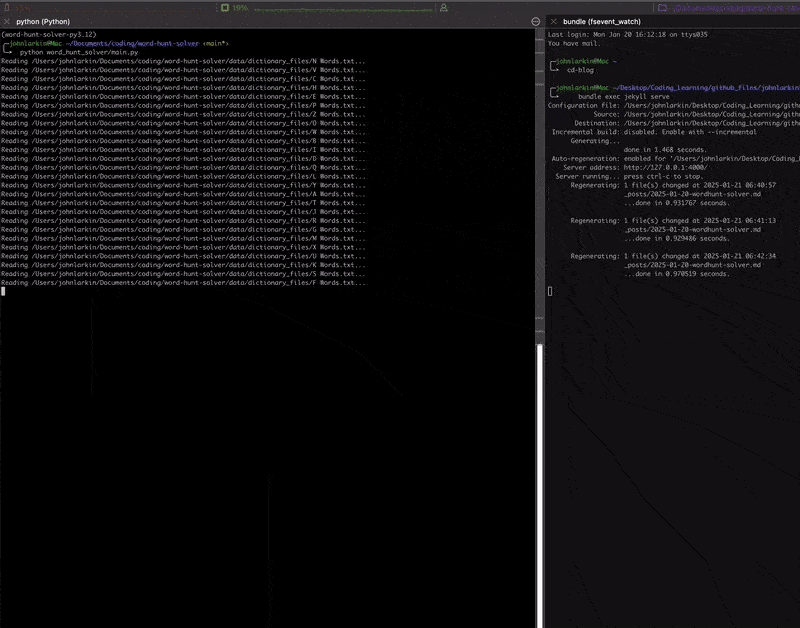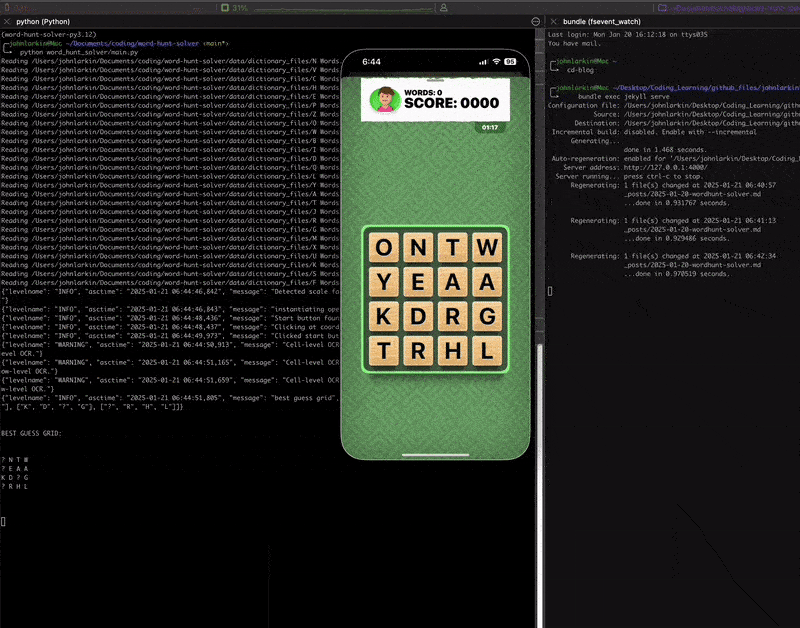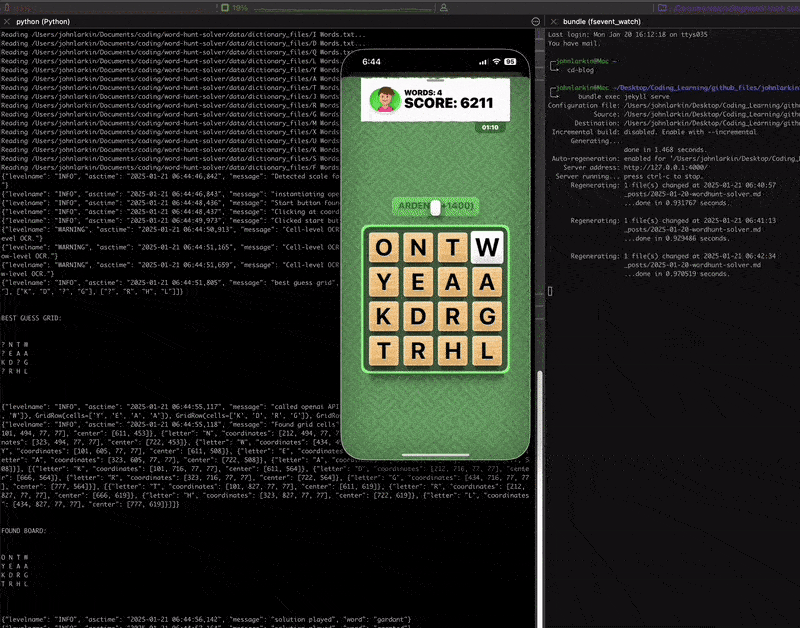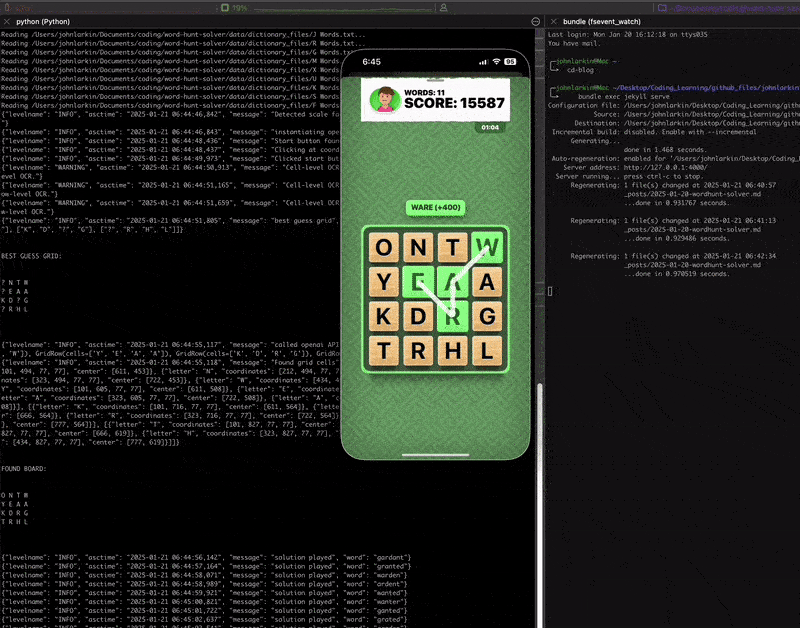
You can’t quite tell but all the mouse interactions from the clicking on the start button to the actual entering and dragging of keywords is all automated.
You can check out the code here.
Tech Stack
This was more of a backend project, but here are some of the pertinent libraries I used, and a Mermaid diagram showcasing this.

Basically, this was all python 3.12, with these libraries being some of the core:
- Computer Vision / Image Processing
opencv2 (4.10.0.84)pytessaract (0.3.13)- As a fall back (and I’ll touch on this more),
openai- Response Format
- Image upload
- Data Structures / Algorithms
- Async file loading using
aiofiles - Custom trie structure
- DFS with path tracking
- Async file loading using
- Automation / Mouse Control
- Utilities
pydanticpython-json-logger
Engineering + Design
This won’t be a long post because the code should be pretty straight forward, but I’ll explore some of the more interesting technical parts of this project.
Tries
I’m going to lead with an example. See the example gif below:
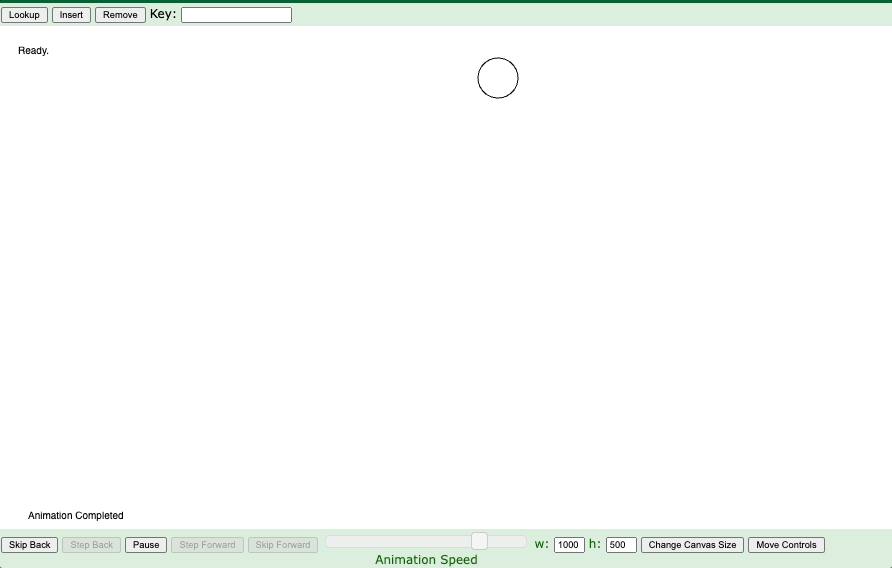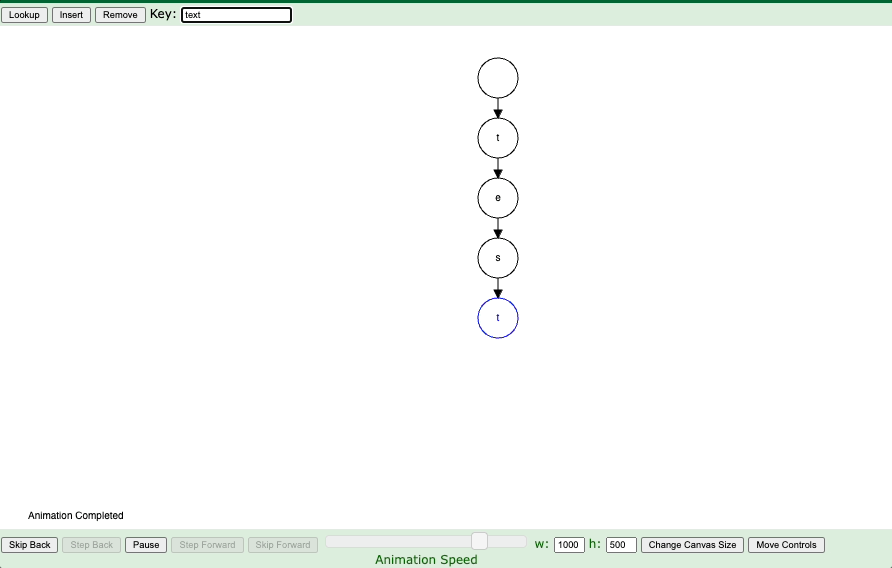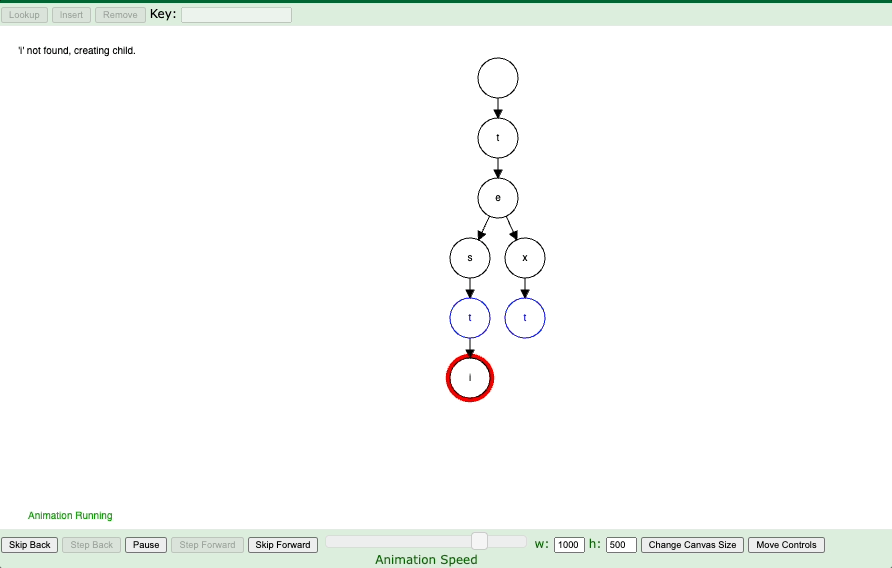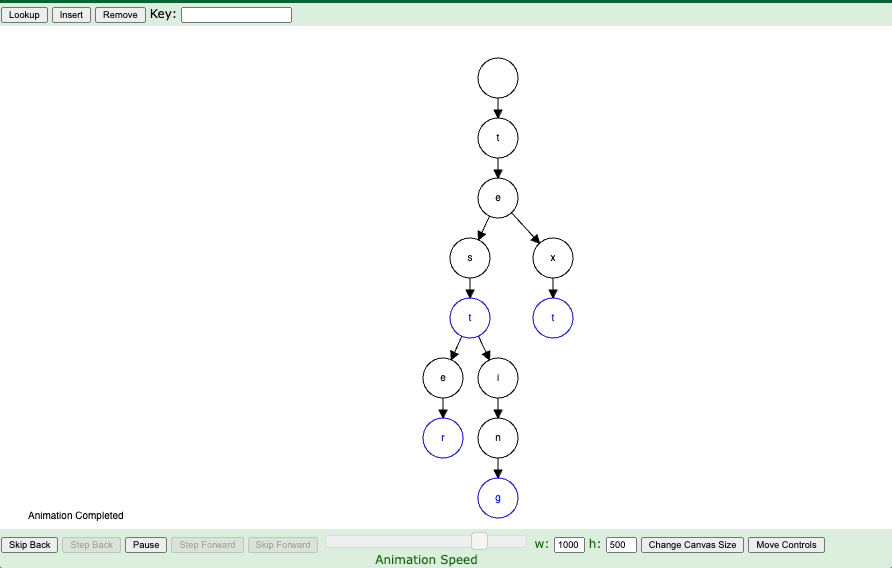
In an effort to make my blog more interactive, you can play around with the trie demo directly. Kudos to the magic of iframes. Give it a whirl below:
This data structure is actually pretty simple to implement some of the base methods in Python. It is basically holding prefixes of strings and so leads to efficient storage and queries on if strings exist and simply can recurse down the trie looking for the prefixes.
Here’s our entire trie structure. We don’t actually recurse because we can just explore in \(O(N)\) where \(N\) is the length of the word.
class TrieNode:
def __init__(self):
self.children: dict[str, TrieNode] = {}
self.is_end_of_word: bool = False
class Trie:
def __init__(self):
self.root: TrieNode = TrieNode()
def insert(self, word: str) -> None:
node = self.root
# traverse, adding more nodes when needed
for char in word:
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
node.is_end_of_word = True
def search(self, word: str) -> bool:
node = self.root # start at root
for char in word:
if char not in node.children:
return False
node = node.children[char]
return node.is_end_of_word
def starts_with(self, prefix: str) -> bool:
node = self.root # start at root
for char in prefix:
if char not in node.children:
return False
node = node.children[char]
return True
Great, and that’s basically all there is to it (for the methods we really need for this example).
aiofiles and Dictionary Loading
Ok so we’ve got our trie, but we obviously need to populate our tree with actual words.
This was actually pretty interesting, but the Scrabble dictionary (which is what I was guessing WordHunt was using) is not actually public. It’s somewhat protected and I wasn’t sure if I was going to load some of this onto Github so I didn’t want to really mess around with it. You can check out more at the official Scrabble website here. At least the LeXpert part here kind of freaked me out:
LeXpert UKNA.lxd contains Collins Scrabble™ Words 2024 (the “word list”) which are the copyright material of HarperCollins Publishers Ltd. You may not use the word list for any purpose including, but not limited to, copying the whole or any part, reverse-engineering, decompiling, editing, disseminating, selling or using for any form of commercial gain.
So instead, I went to here: https://github.com/kloge/The-English-Open-Word-List. This was already on Github and already free, so i feel fine basically pointing to this repo. It contains files titles <char> Words.txt which are just newline delimited text files.
I loaded those up and then inserted them into my trie with this logic:
class AsyncWordLoader:
def __init__(self, dictionary_path: Path, trie: Trie | None = None, logger: Logger = LOGGER) -> None:
self.dictionary_path = dictionary_path
self.trie = trie if trie else Trie()
self.logger = logger
async def read_file(self, file_path: Path) -> None:
self.logger.info("reading file", extra={"file_path": file_path})
async with aiofiles.open(file_path, mode="r") as file:
async for line in file:
word = line.strip()
# we only want to populate greater than 1 word
if word and len(word) > 2:
self.trie.insert(word)
async def load_all_files(self) -> None:
tasks = []
for file in self.dictionary_path.iterdir():
if file.is_file() and file.suffix == ".txt" and not file.name.startswith("_"):
tasks.append(self.read_file(file))
await asyncio.gather(*tasks)
def get_populated_trie(self) -> Trie:
return self.trie
The nice part about using aiofiles is that you can use asyncio to not block at all on the I/O of reading this, so these are all read and populated basically concurrently (but you don’t have to worry about locks on self.trie because asyncio still only uses only one single threaded event loop).
Also note, I filter on words that are > 2 because WordHunt doesn’t accept 2 letter words.
Computer Vision of Seeing and Understanding the Board
So now the more interesting part of this project: how can we see and control what we’re playing?
This stuff is decently specific for MacOS products (iPhone Mirroring, use of Quartz) so just beware... you definitely won't be able to port to Windows or Linux.
Bringing the iPhone to the Front
This was actually bit more annoying than I thought. I tried using pygetwindow but that was not actually that compatible with MacOS devices. It does seem to work well for Windows machines though. So this was the main function that finally did what I wanted:
def bring_iphone_to_front(self) -> bool:
workspace = NSWorkspace.sharedWorkspace()
apps = workspace.runningApplications()
app_name = "iPhone Mirroring"
for app in apps:
if app_name.lower() in app.localizedName().lower():
app.activateWithOptions_(0)
time.sleep(1)
return True
return False
Pressing Start Button
Once we have the iPhone actually visible on the display, we need to actually press the start button.
This is a bit of cv2 and I figured the most deterministic way was to use a template and just match on that. I tried more advanced approaches with using the Hough Line Transform and detecting the edges and relative aspect ratio for an iPhone but that was a bit flakier. So I just provided templates of what we were looking for and this was the pertinent crux of logic:
def find_iphone(self) -> XYWHCoordinates:
self.take_screenshot()
if self.screenshot is None:
raise AssertionError("No screenshot available.")
template = cv2.imread(IPHONE_TEMPLATE_PATH_STR, cv2.IMREAD_GRAYSCALE)
if template is None:
raise ValueError("iPhone template image not found.")
screenshot_gray = cv2.cvtColor(self.screenshot, cv2.COLOR_BGR2GRAY)
if self.debug:
self.debug_show("Screenshot", screenshot_gray)
result = cv2.matchTemplate(screenshot_gray, template, cv2.TM_CCOEFF_NORMED)
_, max_val, _, max_loc = cv2.minMaxLoc(result)
if max_val >= IPHONE_TEMPLATE_MATCH_THRESHOLD:
x, y = max_loc
h, w = template.shape
if self.debug:
annotated = self.screenshot.copy()
cv2.rectangle(annotated, (x, y), (x + w, y + h), (0, 255, 0), 2)
self.debug_show("Detected iPhone", annotated)
self.iphone_coordinates = XYWHCoordinates(x, y, w, h)
return XYWHCoordinates(x, y, w, h)
raise AssertionError("iPhone not found on the screen.")
And here are the relevant templates for the iPhone and start button respectively:
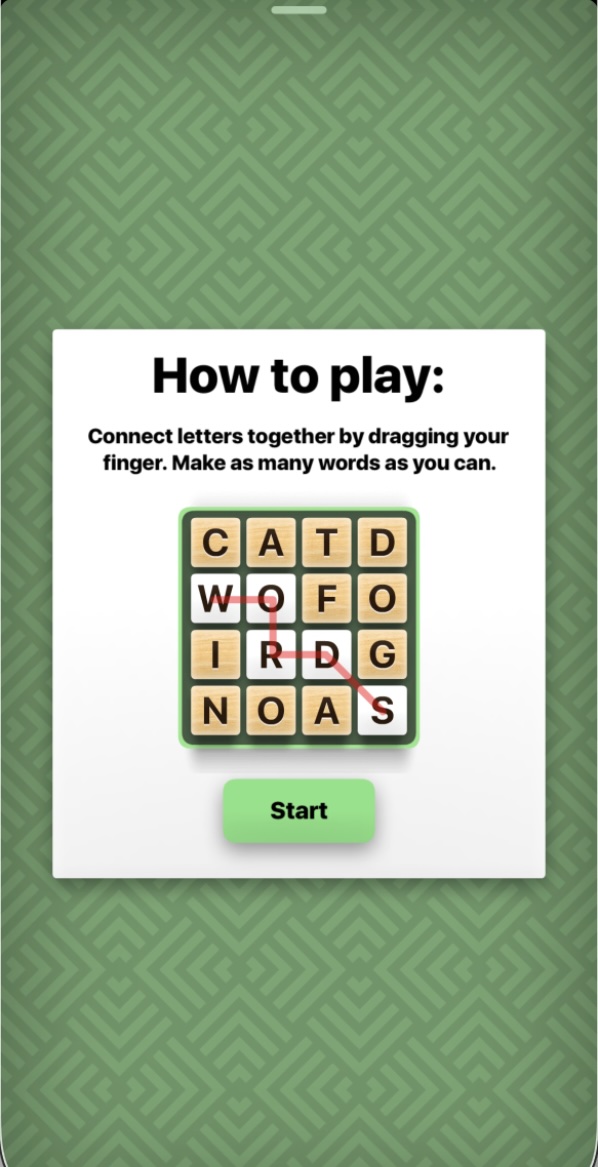

Retina Display
The code above will generally work very well. However, one interesting point that arose was the distinction between pixel space from pyautogui and cv2.
Basically on first pass, I was navigating and clicking to somewhere that was well off my screen. After a bit of sleuthing, I found the reason was because I was using a Retina display.
Basically, this is an interesting intentional decision from the OpenCV and pyautogui libraries. OpenCV sees every retina pixel at full resolution, whereas pyautogui is more just worried about the lower density coordinate space. With retina display, MacOS basically uses a coordinate system instead of a pixel system, because at each point there are two pixels.
This has been explored multiple times. Here are a couple examples:
PyAutoGui LocateOnScreen - how to overcome Mac retina display issues
byu/No-Age9807 inpyautogui
or here.
📸 Detecting the Grid
This was probably the most interesting part of this problem.
I tried this approach entirely using pytessaract and grid detection. We took these steps to find the grid:
- Convert to gray
cv2.cvtColor - Gaussian blur
cv2.GaussianBlur(the thought here was to reduce noise) - Canny edge detection
cv2.Canny - Contours detected
approxPolyDPof contours- Sort by largest area (this is now our grid)
- Divide into present dimensions (we know we’re normally playing 4 x 4)
- Account for some margin
- Divide up each grid cell
- Use
pytessaractwith--psm 10to indicate we’re only parsing a single cell - Build up that grid
This works decently well. Let me visually walk you through what’s going on.

0. Original

1. Grayscale

2. Blurred

3. Canny Edge Detection

4. Contours Detected
After doing this, we’re now at step 5. We ensure that there are four edges of our largest contour by using cv2.approxPolyDP and also cv2.arcLength.
Once we have that grid, we know that there’s a bit of margin so we can trim some of that with this logic.
bounding_x, bounding_y, bounding_w, bounding_h = cv2.boundingRect(grid_contour)
margin_x = int(margin_ratio * bounding_w)
margin_y = int(margin_ratio * bounding_h)
x = max(bounding_x + margin_x, 0)
y = max(bounding_y + margin_y, 0)
w = max(bounding_w - 2 * margin_x, 1)
h = max(bounding_h - 2 * margin_y, 1)
extracted_grid = iphone_screen[y : y + h, x : x + w]
if self.debug:
self.debug_show("Extracted Grid", extracted_grid)
cell_width = w // grid_size[1]
cell_height = h // grid_size[0]
# draw for debugging
# other code
# best attempt at using OCR + maybe LLMs as a fallback
grid_cells = self.grid_parser.parse_grid(
grid_size=grid_size,
cell_width=cell_width,
cell_height=cell_height,
x=x,
y=y,
w=w,
h=h,
iphone_x=iphone_x,
iphone_y=iphone_y,
iphone_screen=iphone_screen,
)
This works pretty well, and you can see our detected grid here:

Parsing the Grid
Now comes the actual logic of detecting the coordinates and the actual letter of our grid.
My instincts were just to use pytessaract for all of this, but I was incredibly surprised by how finicky it was to actually get perfect character recognition.
Let’s look at an actual example.
Here are the actual images that I passed to pytessaract to detect the images, followed by our final results.




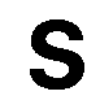
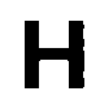

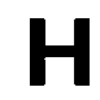



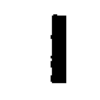



What do you think? How many out of these would you be able to detect? How many do you think pytessaract got?
Here’s the result:
It specifically missed the O which makes sense as I am using this pytessaract filter:
letter = pytesseract.image_to_string(
resized_cell,
lang="eng",
config="--psm 10 -c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ0",
).strip()
And I know some of you CV wizards and experts - maybe even Matt - are saying, oh well I mean the edges are blurred and that probably isn’t going to be reliable or like there’s a certain trick about the resizing.
I tried to cover these with this bit of code:
cell_gray = cv2.cvtColor(cell, cv2.COLOR_BGR2GRAY)
_, thresholded_cell = cv2.threshold(cell_gray, 150, 255, cv2.THRESH_BINARY)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))
sharpened = cv2.morphologyEx(thresholded_cell, cv2.MORPH_CLOSE, kernel)
resized_cell = cv2.resize(sharpened, (100, 100), interpolation=cv2.INTER_LINEAR)
if self.debug:
self.debug_show(f"Cell {row}-{col}", resized_cell)
letter = pytesseract.image_to_string(
resized_cell,
lang="eng",
config="--psm 10 -c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ0",
).strip()
And it slightly improved the results but didn’t solve all edgecases. Basically, these steps are a slight cleanup to try and apply a morphological operator MORPH_CLOSE using the kernel operator (basically that 2x2 grid) to improve the edges and sharpen the image for pytessaract. Perhaps I was doing more harm than good, but in my testing, I did see a slight improvement.
So given that… what do we do? Here’s the driving though:
Should I invest more time in a more rigorous OCR and preprocessing steps to this random side project, or should I - as I am guessing will be embedded in millions of software decisions over the next decade - just toss it over the window to a more sophisticated LLM?
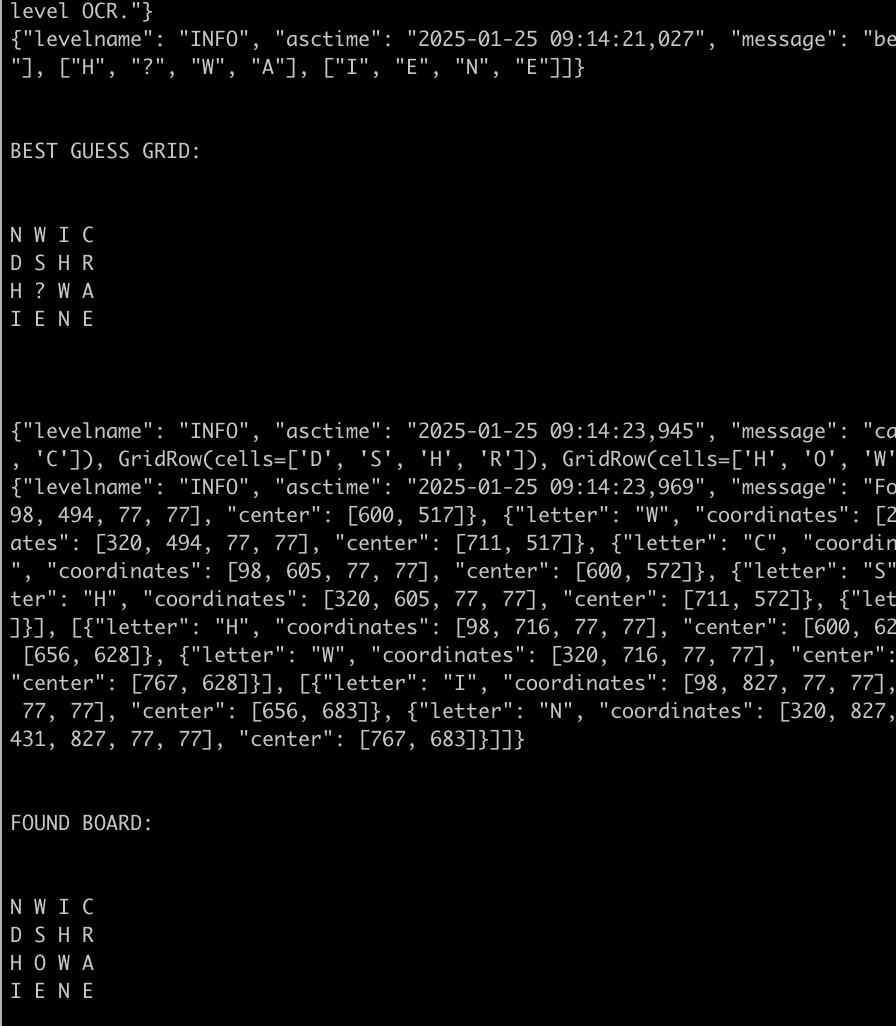
🤖 Combined Flow with OpenAI LLM Fallback
I figured the prior knowledge of OCR and my “best guess grid” is still going to be somewhat helpful, and we could combine this, with the converted grid image, to have a fairly resilient approach.
Check the crux of it out here:
# i'm going to use these as the response_format for OpenAI
class GridRow(BaseModel):
cells: List[str]
# more specifically check the `response_format` below
class Grid(BaseModel):
rows: List[GridRow]
...
def refine_with_openai(self, grid_cells: List[List[GridCell]], extracted_grid: np.ndarray) -> List[List[GridCell]]:
_, buffer = cv2.imencode(".png", extracted_grid)
base64_image = base64.b64encode(buffer).decode("utf-8")
# create our "best guess" grid with '?' for unknowns
best_guess_grid = [[cell.letter if cell.letter is not None else "?" for cell in row] for row in grid_cells]
best_guess_grid_str = "\n".join([" ".join(row) for row in best_guess_grid])
response = self.client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are an expert in parsing and refining grid-based images."},
{
"role": "user",
"content": [
{
"type": "text",
"text": (
f"Here is a best guess grid where '?' represents unknown values:\n"
f"{best_guess_grid_str}\n"
"Please refine the grid based on the image provided below.\n"
"Extract and parse the grid from this image."
),
},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{base64_image}"},
},
],
},
],
max_tokens=300,
response_format=Grid,
)
parsed_grid = response.choices[0].message.parsed
refined_grid = [
[
GridCell(
letter=parsed_grid.rows[row].cells[col],
coordinates=grid_cells[row][col].coordinates,
center=grid_cells[row][col].center,
)
for col in range(len(parsed_grid.rows[row].cells))
]
for row in range(len(parsed_grid.rows))
]
return refined_grid
Given this, eventually we finally ended up at our ideal graphing:

Solver Logic
Ok so great! So now we have our list of list of GridCells. This is our board basically. I wrote a small wrapper for our Board that the solver takes as an input.
The whole idea behind the solver is that we’re going to try each location and DFS at each location in the grid, trying to find all the possible words at each path. Our termination conditions are going to be if we’ve already visited that cell before (the visited set is created fresh per each starting cell), or if our current word isn’t in our trie, then we know we’re safe to not explore that path anymore. Otherwise, we’ll recurse deeper and continue our path.
One optimization I made because I knew we wanted to store our highest scoring paths first, was to use a priority queue and enqueue on that by the path length. heapq in Python is a min-heap by default, but we want to prioritize longer paths, so the more negative, the better it is for us. That’s why we use the -len() and why we basically get free ordering as a result from here: [heapq.heappop(self.priority_queue)[1] for _ in range(len(self.priority_queue))].
In totality, here is our code for solving:
class WordHuntSolver:
def __init__(
self,
board: Board,
trie: Trie,
) -> None:
self.board = board
self.trie = trie
self.solution_paths: list[SolutionPath] = []
self.priority_queue: list[tuple[int, SolutionPath]] = []
self.found_words: set[str] = set()
def is_in_matrix(self, row: int, col: int) -> bool:
return 0 <= row < len(self.board) and 0 <= col < len(self.board[row])
def get_neighbors(self, row: int, col: int) -> list[tuple[int, int]]:
directions = [(-1, -1), (-1, 0), (-1, 1), (0, -1), (0, 1), (1, -1), (1, 0), (1, 1)]
neighbors = []
for dx, dy in directions:
new_row, new_col = row + dx, col + dy
if self.is_in_matrix(new_row, new_col):
neighbors.append(Point(new_row, new_col))
return neighbors
def dfs(self, row: int, col: int, path: list[GridCell], visited: Set[tuple[int, int]]) -> None:
if (row, col) in visited:
return
cell = self.board.get_cell(col, row)
path.append(cell)
# Form the current word
current_word = "".join([cell.letter for cell in path])
current_word = current_word.lower()
# Check if the current word is a valid prefix
if not self.trie.starts_with(current_word):
path.pop() # Backtrack
return
# If it's a valid word, save the path
if self.trie.search(current_word) and current_word not in self.found_words:
self.found_words.add(current_word)
# if we want a like 'going easy' mode, uncomment this
# heapq.heappush(self.priority_queue, (len(path), SolutionPath(path=path[:], word=current_word)))
heapq.heappush(self.priority_queue, (-len(path), SolutionPath(path=path[:], word=current_word)))
# mark the current cell as visited
visited.add((row, col))
# recurse on all valid neighbors
for neighbor_row, neighbor_col in self.get_neighbors(row, col):
self.dfs(neighbor_row, neighbor_col, path, visited)
# backtrace
visited.remove((row, col))
path.pop()
def solve(self) -> list[SolutionPath]:
for row in range(len(self.board)):
for col in range(len(self.board[row])):
self.dfs(row, col, [], set())
# here's where we use our priority queue because we have what's already
# sorted by length
self.solution_paths = [heapq.heappop(self.priority_queue)[1] for _ in range(len(self.priority_queue))]
return self.solution_paths
The SolutionPaths are then used for logging and to actually play the word.
Conclusion
This was a very fun project, and it was 1) satisfying to finally get a win in WordHunt, but 2) fun to get back to OpenCV, explore using OpenAI LLM calls with image upload (which I hadn’t done before), and automate my computer’s action some.
There are some perhaps larger questions about the specific decision point between more preprocessing and OCR for pytessaract or just throwing it over the wall to LLMs that I think are an interesting question, but I’ll try to write about that another time.
Additionally, I don’t love using some of those OpenCV libraries without further understanding more about the internals of how those algorithms work, so I want to do a continuation of that.
Overall though, I’m happy with how I organized and structured the code, and looking forward to sharing this post.
As always, if you all have any helpful comments, constructive feedback, or questions, feel free to reach out. Always happy to chat.