
Motivation
The real motivation was this was an interesting problem and I wanted to get a more hands on grip with RAG, vector databases, and some of the tech that has come out of the LLM boom. Here are some screenshots of the finished product, but feel free to watch the videos below too:
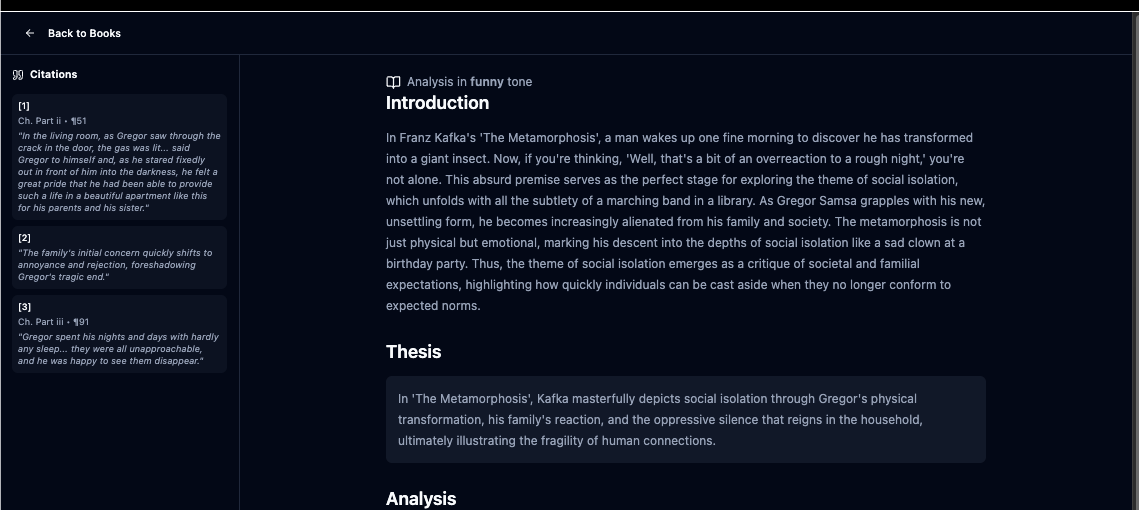
I was hoping that AI wouldn’t replace humor, but honestly this ^ isn’t half bad.
Introduction
There’s not too much of an introduction here. This was a challenge that I saw and I thought it would be fun to put aside a couple of hours and attack this. I actually am going to default to these videos as a summary, in case you don’t want to do that much reading.
Figure 1: Book BrAin Demo Part 1
Figure 2: Book BrAin Demo Part 2
Tech Stack
- IDE
- Cursor (annoying and I don’t really use the AI features that that much, but still)
- Databases
- Backend
- Frontend
- Client
- Typescript / React
- Client
Ideally, in the future, I could have looked at:
Goal
The problem was stated as this:
[the] job is to ingest the text from each book into a language model and comparatively analyze how each work deals with the theme of social isolation. What are the authors’ points of view on this subject, and what parts of the novel corroborate these claims? Your output will be a 5 paragraph book report (also generated by a language model) that states a clear thesis statement, makes clear arguments based on the content of each novel, and accurately cites sections of each novel, culminating in a concluding paragraph to summarize the arguments.
High Level Approach
My high level approach to this project and one way to make it differentiate was that I wanted to build a corresponding frontend portion and make it a bit more interactive.
There’s a lot more I could have done here obviously - both on the frontend and backend. But the high level approach was as such:
- Run
ingest_books.pytext_extractionfrom the various input file formatchunking- parses the chunked text usingfrom langchain.text_splitter.RecursiveCharacterTextSplitter- Tried to do some metadata information like what page are we on? , what chapter are we on?, etc
embedding-openai.embeddings.createwithtext-embedding-3-smallvector_storage- create aqdrant_client.models.PointStructand then upload usingqdrant_client.QdrantClient
- Use
OpenAI’s embedding model and get our query prompt- This is basically asking about the theme in the book and looking in this high dimensional space for the closest embedding as our query vector
query_prompt = get_query_prompt(theme, book_title)
query_response = self._client.embeddings.create(
model=self._embedding_model,
input=query_prompt,
encoding_format="float",
)
query_vector = query_response.data[0].embedding
- Get those closest search results in our embedding space
search_result = self._qdrant_client.search(
collection_name=self._collection_name,
query_vector=query_vector,
query_filter=Filter(must=[FieldCondition(key="book_id", match=MatchValue(value=book_id))]),
limit=num_passages,
)
passages: list[ThematicPassage] = []
- Run OpenAI prompt doing more specific theme analysis providing the passages and using
response_formatto get a well structured Pydantic response - Run OpenAI prompt doing more specific writing production providing the theme analysis and included citations threaded
- Save these final Pydantic model to a file
- FastAPI serves up these models to the client
- (note: the idea is that some form of this could happen online if need be)
- Client makes queries for the themes and asks for various analysis
Theory
I’m on a bit of a time crunch right now, so not going to cover this in a ton of detail, but ultimately I want to do some writeups of some of the 3Blue1Brown videos that are so good in this space.
Technical Design
I have recently been using mermaid, which honestly I’ve only really heard about because of signing up for Claude. That’s probably another blog post about that, but the TLDR is that Claude showed a mermaid diagram to me at one point, and I’ve started to use it in other projects. Claude seems better at doing this than ChatGPT but I’m guessing that’s just part of the artifacts feature.
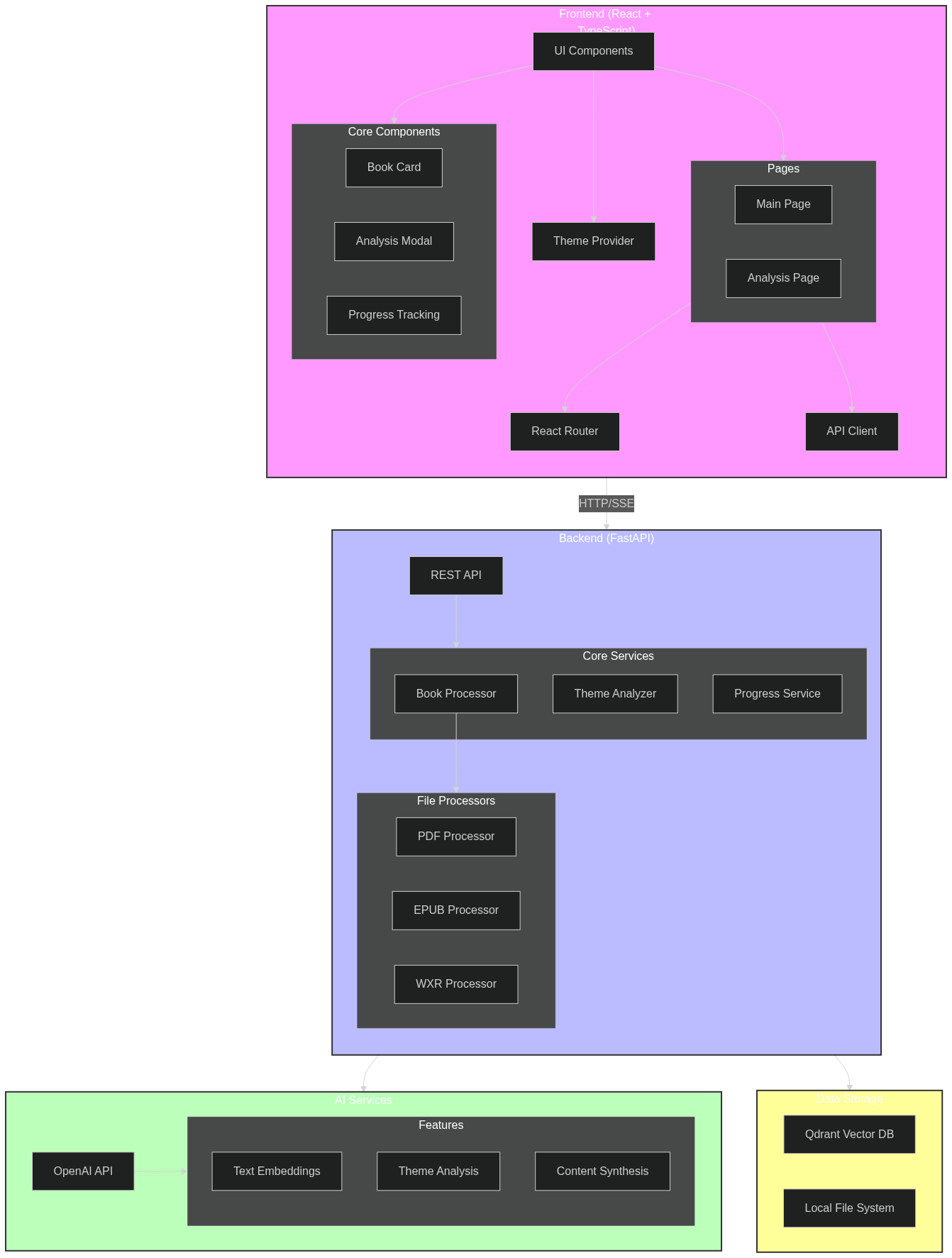
So there’s some elements here that we aren’t actually fully using.
I had some set up where we had some ProgressTracker that was streaming events back to the client when there was a book upload. My thinking was we could have the SSE events show the various steps (file_upload -> text_extraction -> chunking -> embedding -> vector_storage -> cleanup). However, I didn’t actually get to the book upload portion just because I didn’t want to burn the time. The general idea is that as some background task, we’ll upload a book doing like this:
@app.post("/api/books/upload")
async def upload_book(
background_tasks: BackgroundTasks,
file: UploadFile = File(...),
book_id: Optional[str] = None
) -> UploadResponse:
And we’ll basically take from the frontend the HTTP multipart form data (which would handle chunking up the file and all that).
However, I didn’t get to that so let’s dive into what I did accomplish.
Backend
We’re using Python3.12 on the backend. For the web framework and to serve requests, we’re using FastAPI. I have used FastAPI at work a good bit for some of the parlay pricing work that I’ve done and I’m generally a fan for prototyping and tying in with other Python packages. It’s very quick to spin up.
For Python package management, I’m using poetry, of which I’m a huge fan. Way better than pipenv. I know Astral has been pushing uv and that has also made some pretty insane leaps and perf benchmarks, so I’ll plan on trying that soon.
Ingestion
On the ingestion front, as kind of outlined above, I’m using Qdrant which is an open source vector database that the community has really adopted. I’m not being as sophisticated as I want with the text splitting and chunking, but we’re using Langchain’s from langchain.text_splitter import RecursiveCharacterTextSplitter with whatever we can basically pull out from the WXR, EPUB, or PDF file.
FastAPI
There’s not too much going on here, but here’s my OpenAPI json generated from my FastAPI code. I’ve only included the paths in terms of the OpenAPI json, but I also shared my Pydantic models (just for brevity).
{
"openapi": "3.1.0",
"info": {
"title": "Book BrAIn API",
"description": "API for book analysis and theme exploration",
"version": "1.0.0"
},
"paths": {
"/api/analysis/content/{book_id}/{tone}": {
"get": {
"tags": ["analysis"],
"summary": "Get Analysis",
"description": "Get the analysis for a specific book and tone.",
"operationId": "get_analysis_api_analysis_content__book_id___tone__get",
"parameters": [
{
"name": "book_id",
"in": "path",
"required": true,
"schema": {
"type": "string",
"title": "Book Id"
}
},
{
"name": "tone",
"in": "path",
"required": true,
"schema": {
"type": "string",
"title": "Tone"
}
}
],
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/FinalEssay"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
},
"/api/analysis/tones/{book_id}": {
"get": {
"tags": ["analysis"],
"summary": "Get Available Tones",
"description": "Get list of available tones for a book's analysis.",
"operationId": "get_available_tones_api_analysis_tones__book_id__get",
"parameters": [
{
"name": "book_id",
"in": "path",
"required": true,
"schema": {
"type": "string",
"title": "Book Id"
}
}
],
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/AvailableTonesResponse"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
}
}
}
And here are some of my Pydantic models:
class LiteraryDevice(BaseModel):
name: str = Field(description="Name of the literary device")
description: str = Field(description="How the device is used in this context")
examples: List[str] = Field(description="Textual examples of the device")
class Config:
extra = "forbid"
class ThematicEvidence(BaseModel):
quote: str = Field(description="The relevant quote from the text")
citation: str = Field(description="Formatted citation for the quote")
analysis: str = Field(description="Analysis of how this evidence supports the point")
context_before: str | None = Field(description="Text preceding the quote")
context_after: str | None = Field(description="Text following the quote")
class Config:
extra = "forbid"
class Citation(BaseModel):
text: str = Field(description="The quoted text or passage")
chapter: str | None = Field(description="Chapter reference, if applicable")
page: int | None = Field(description="Page number reference, if applicable")
paragraph: int | None = Field(description="Paragraph reference within the chapter or text")
source: str = Field(description="Full citation source (e.g., book title and edition)")
class Config:
extra = "forbid"
class InitialAnalysis(BaseModel):
theme_manifestations: List[str] = Field(description="Ways the theme manifests in the text")
theme_development: str = Field(description="How the theme develops through the work")
literary_devices: List[LiteraryDevice] = Field(description="Literary devices used to express the theme")
key_patterns: List[str] = Field(description="Important patterns in theme presentation")
passage_connections: List[str] = Field(description="Connections between different passages")
overall_significance: str = Field(description="Theme's broader significance in the work")
passage_citations: List[Citation] = Field(description="List of key passages and their detailed citations")
class Config:
extra = "forbid"
class InlineCitation(BaseModel):
text: str = Field(description="A sentence or passage potentially containing inline citations.")
citation: Optional[str] = Field(
description="The citation reference formatted concisely as inline text, e.g., [ch 2, pg 10, para 3].",
default=None,
)
class BodyParagraph(BaseModel):
sentences: List[InlineCitation] = Field(description="List of sentences with optional inline citations.")
class FinalEssay(BaseModel):
introduction: str = Field(description="Introduction paragraph ending with thesis statement")
thesis: str = Field(description="Thesis statement about the theme")
body_paragraphs: List[BodyParagraph] = Field(
description="Each body paragraph contains the text and associated citation."
)
conclusion: str = Field(description="Conclusion paragraph synthesizing the analysis")
citations_used: List[Citation] = Field(description="All unique citations used in the essay")
class Config:
extra = "forbid"
Frontend
On the frontend, I kept it very simple. I used Vite which I had been wanting to use for awhile. And then of course I used shadcn/ui which I have been using more and more and the community has really loved.
This was great, it was pretty easy to iterate and move quickly here given I wanted to timebox this. And then yeah keeping things as isolated components made it very easy to work with Claude and such.
Demo
Here’s a screen capture if curious.
gpt-4o-mini... kinda funny?
Design Questions
Let’s dive in.
Ingestion
How should you ingest the different file types for the books?
Yeah so this was an interesting thought. Honestly, I was at this event in NYC a couple of weeks (or maybe months ago now :grimace:) and a woman gave a beautiful presentation about unstructured.io, so thought about using it there, but kind of felt like overkill.
So I just opted for known Python libraries and looking at the incoming file and the file suffix.
One other idea I had is if we didn’t have such helpful information as the right file suffix, or we had a bad actor, then we could use openai and just peek the bit of the file to see if we could determine which processing flow to use.
Are there any general modules out there, or should you implement your own parser for any reason?
Yeah lots of general modules out there. Again, the ones I used are: pypdf, ebooklib, and bs4 (i.e. beautiful soup).
However, those didn’t really have great detection of some of the metadata that would make for helpful citations, so I did take a little bit of a custom approach here. For example, for the Wordpress XML:
async def _extract_wxr_metadata(self, item: ET.Element) -> WXRMetadata:
"""Extract metadata from WXR item element with fallback values."""
namespaces = {
"wp": "http://wordpress.org/export/1.2/"
}
def get_element_text(elem: ET.Element, tag: str, default: str = "") -> str:
el = elem.find(tag, namespaces)
return el.text.strip() if el is not None and el.text else default
def parse_date(date_str: str) -> datetime:
"""Parse date with fallback to current time if invalid."""
if not date_str:
return datetime.now()
try:
return datetime.strptime(date_str, "%Y-%m-%d %H:%M:%S")
except ValueError:
try:
return datetime.strptime(date_str, "%Y-%m-%d")
except ValueError:
return datetime.now()
return WXRMetadata(
title=get_element_text(item, "title"),
post_date=parse_date(get_element_text(item, "wp:post_date_gmt")),
post_type=get_element_text(item, "wp:post_type", "post"),
post_id=get_element_text(item, "wp:post_id", str(uuid.uuid4())),
post_parent=get_element_text(item, "wp:post_parent"),
menu_order=int(get_element_text(item, "wp:menu_order", "0")),
categories=[cat.text for cat in item.findall("category") if cat.text is not None],
custom_metadata={
get_element_text(meta, "wp:meta_key"): get_element_text(meta, "wp:meta_value")
for meta in item.findall(".//wp:postmeta", namespaces)
if get_element_text(meta, "wp:meta_key") and get_element_text(meta, "wp:meta_value")
},
)
Note there’s no reason this needs to be async that’s just a bad habit from me. And here’s an example of the PDF one that is perhaps a bit more readable:
async def process_pdf(self, file_path: str, book_id: str) -> List[ProcessedChunk]:
"""Process PDF file with enhanced metadata extraction."""
await self._progress_service.update_progress(book_id, ProcessingStep.TEXT_EXTRACTION, 0.0)
reader = pypdf.PdfReader(file_path)
total_pages = len(reader.pages)
processed_chunks: List[ProcessedChunk] = []
current_chapter = None
total_paragraph_count = 0
chapter_paragraph_count = 0
for page_num, page in enumerate(reader.pages, 1):
text = page.extract_text()
if not text:
continue
# Split into paragraphs
paragraphs = [p.strip() for p in text.split("\n\n") if p.strip()]
# Check first paragraph for chapter heading
if paragraphs:
potential_chapter = ChapterInfo.parse_chapter_title(paragraphs[0])
if potential_chapter:
current_chapter = potential_chapter
current_chapter.start_position = total_paragraph_count
chapter_paragraph_count = 0
paragraphs = paragraphs[1:] # Remove chapter heading
for paragraph in paragraphs:
if paragraph.strip():
metadata = TextMetadata(
chapter=current_chapter.title if current_chapter else None,
chapter_number=current_chapter.number if current_chapter else None,
chapter_paragraph=chapter_paragraph_count,
total_paragraph=total_paragraph_count,
page_number=page_num,
)
processed_chunks.append(ProcessedChunk(text=paragraph, metadata=metadata))
chapter_paragraph_count += 1
total_paragraph_count += 1
await self._progress_service.update_progress(
book_id, ProcessingStep.TEXT_EXTRACTION, page_num / total_pages
)
return await self._add_context_to_chunks(processed_chunks)
Language Models
Once ingested, what language model(s) should you use to process and analyze the books?
I didn’t experiment too much with this. I used gpt-4o-mini because I had used it before (and my OpenAI account was already loaded). It also has a reasonable context window and yeah I figured it was as good as any.
What is the context length of the model you use, and will you be able to fit the entire book into context?
Yeah so this was an interesting point. I didn’t actually test this experiment but my hypothesis was that if I passed the whole context I would lose the metadata about which page number / paragraph number / chapter / etc, we were actually pulling from.
However, perhaps just given what it was trained on it would have been able to find specific page numbers or better references.
But yeah, in terms of context length, gpt-4o-mini has a context length of 128K tokens. And roughly 1500 words is about 2048 tokens, so:
- The Bell Jar – 66.5k words ~= 90k tokens
- The Metamorphosis ~ 22.185 words ~= 30k tokens
- The Stranger - ~36k words ~= 49k tokens
So yeah these could all probably all fit in a context window.
The thing is that’s a little boring and honestly I’ve done testing on massive context windows and where the engineering complexity in that.
So yeah my take was that it’s more fun to do chunking -> vector database -> cosine similarity in a high(ish) dimensional space, and then go from there and find out which passages might be pertinent
If not, how should you break down the text?
Yeah I used langchain and did chunking with some overlap to break down the text.
Model Differentiation
Should the model you use for analysis be the same model you use for writing the report?
This was an interesting idea. I’m not sure if some models are better at synthesis or whatever. I certainly wasn’t about to pay to use o1-preview or even gpt-4 over gpt-4o-mini given I just didn’t care about that much level of sophistication or analysis.
However, I did change the system prompts based on the theme analyzer vs the writer. My hope was that this led to more insightful theme analysis vs a better writer. Here’s an example:
def get_analysis_system_prompt() -> str:
"""Return the system prompt for the thematic analysis phase."""
return """You are an expert at analyzing literary themes and patterns. Your role is to:
- Identify explicit and subtle theme manifestations
- Recognize literary devices and techniques
- Consider historical and cultural context
- Map how themes develop across the text
- Find connections between different passages
- Identify patterns in theme presentation
Provide your analysis in structured JSON exactly matching the specified format."""
def get_writing_system_prompt(tone: str) -> str:
"""Return the system prompt for the writing phase."""
return f"""You are an expert at crafting literary analysis essays. You should adopt a {tone} tone in your answer.
Your role is to:
- Structure arguments logically and coherently
- Use precise literary terminology appropriately, keeping your {tone} tone in mind.
- Maintain the requested tone while being engaging
- Format citations consistently and properly
- Connect evidence to interpretations clearly
- Balance academic rigor with accessibility
Format your response in structured JSON exactly matching the specified format."""
Prompts
What prompts should you use for summarizing/analyzing the texts?
See above, but used those as the system prompts and then specific user prompts for analysis vs writing.
What about generating the report?
Again, see above, but basically:
def get_writing_prompt(analysis: InitialAnalysis, theme: str, book_title: str, tone: str) -> str:
"""Generate the writing prompt to structure the analysis essay."""
return f"""Using this thematic analysis:
{analysis.model_dump_json(indent=2)}
Write a formal essay about how {theme} functions in "{book_title}" with a {tone} tone.
Please target a length of 2000-3000 words.
Structure:
- Introduction paragraph ending with the thesis statement.
- Three body paragraphs, each exploring a specific aspect of the theme, referencing detailed citations.
- Conclusion synthesizing the analysis.
Response format:
{{
"introduction": "Intro paragraph ending in thesis",
"thesis": "Thesis statement",
"body_paragraphs": [
{{
"sentences": [
{{
"text": "Sentence 1 of paragraph with potential inline citation.",
"citation": "Inline citation reference, if applicable."
}},
{{
"text": "Sentence 2 of paragraph.",
"citation": null
}}
]
}},
{{
"sentences": [
{{
"text": "Sentence 1 of paragraph with potential inline citation.",
"citation": "Inline citation reference, if applicable."
}},
{{
"text": "Sentence 2 of paragraph.",
"citation": null
}}
]
}},
{{
"sentences": [
{{
"text": "Sentence 1 of paragraph with potential inline citation.",
"citation": "Inline citation reference, if applicable."
}},
{{
"text": "Sentence 2 of paragraph.",
"citation": null
}}
]
}}
],
"conclusion": "Conclusion paragraph summarizing analysis",
"citations_used": [
{{
"text": "Quoted text",
"chapter": "Chapter reference, if applicable",
"page": Page number,
"paragraph": Paragraph number,
"source": "Full source reference"
}}
]
}}"""
Should it all be 1 prompt, or should different parts of the report be generated by different prompts (or even models)?
I actually should have tested this more, but I think it is fine to have it as multiple prompts. You kind of lose some information I think on the pass between one response to another input, but I think it’s probably worth it here.
Other Tools
Outside of the LLMs themselves, what other tools should you use in this process? Vector DBs, indexers, RAG tooling, etc?
Yup, I used Qdrant and I would have liked to use indexers and a more agentic workflow and provide a langchain agent with tools or something for the literary analysis. Maybe an existing API to check for literary references or something like that.
Conclusion
This was a really fun project to get my hands dirty with some text extraction and chunking. I haven’t used langchain nearly as much as I’ve wanted so this at least let me get my hands slightly dirty. And the other huge win was I got exposure to Qdrant which I have to image I’ll use again in the future.
Next Steps
There’s a laundry list but here are some.
- Desired Features:
- Custom theme selection
- Book upload functionality
- Multi-theme analysis
- Comparative analysis between books
- Enhanced citation system
- User authentication and saved analyses
- Technology: