
You know what kinda sucks? A lot of basic features in iMessages on both macOS and iOS. So I’ve built a command line tool dubbed messages to help alleviate some of those pains.
Background
I have a few complaints and feature requests that I think would be really nice to have with iMessages. There’s a lot that lefts to be desired with searching and aggregating text messages in iMessage.
However, a pretty simple workaround is utilizing the sqlite3 database that’s populated once you set up iMessage if you have a Mac. I haven’t done any research on Windows platforms, so I’ll leave that as an exercise to the reader.
Note, if you’re just interested in code, you can skip all this and check out this repo.
Introduction
What I did throughout this project was built a small command line tool (or CLI) tool so that you could more easily and more performantly interact with your iMessages.
Check out some of the features below.
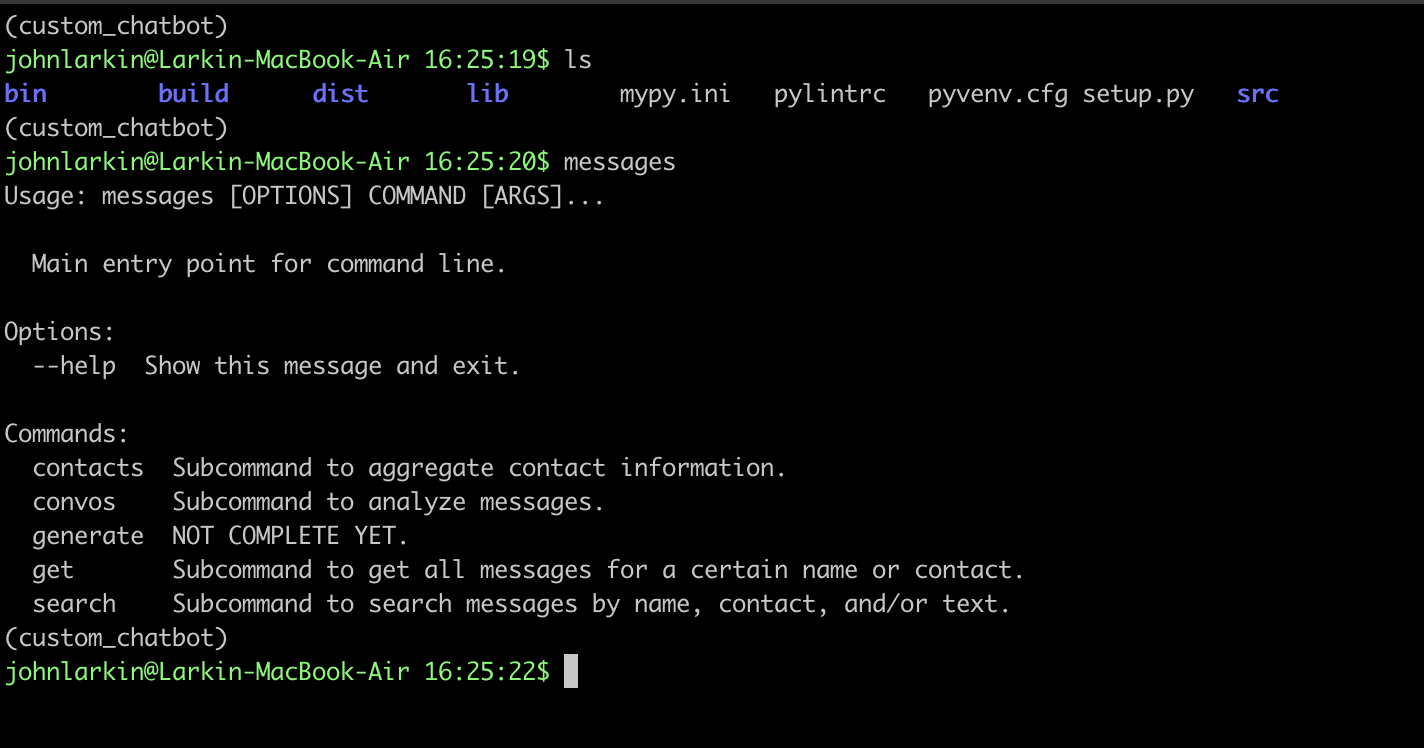
Existing Features
- Enhanced Search
- Search for a string of text on a specific day, by a specific contact, or just generally.
- Message Dump
- Scrolling back in your messages and aggregating all of that into a single stream is not easy to do
- You should be able to dump all of your messages from a specific person or number on a certain date
- Light Trend and Sentiment Analysis
- Aggregated VADER analysis on messages
- Top texted friends
- Total number of distinct messages
Future Features
Some of these are in the pipeline, and I’m hoping to do a follow up post expanding on some of these in the near future.
- word cloud across all messages ever sent / received to see overarching trends
--beforeand--afterfilters forsearchso that you can specify how many messages to look before or after a given search string- This is similar to
grep’s-Band-Aarguments
- This is similar to
- model generation
- I will cover this in another post
- expand functionality for group chats
- search over a given time range
iMessage Sqlite Table Schema
At a high level, the following tables were available:
sqlite> .tables
_SqliteDatabaseProperties
kvtable
attachment - metadata and storage location
message - all messages sent and received
chat - a collection of your messages (both direct and group)
message_attachment_join - join table
chat_handle_join - join table
message_processing_task -
chat_message_join
sync_deleted_attachments
deleted_messages
sync_deleted_chats
handle - metadata about chats
sync_deleted_messages
The main tables that we utilize to get information are the chat and message tables, as well as the join tables. There are additional tables we use to pull in contact information.
Technical Details
Note: all these examples are going to be masked. I created some light shuffling and filtering based on the environment variable MASK_PII_DATA, so feel free to use that accordingly as well. If you also want to mask the message text itself, you can also specify the MASK_MESSAGE_TEXT environment variable (as I’ll show in some examples).
Here’s an overivew of what you’ll get greeted with when you run the messages command.
Before we dive into the functionality, I wanted to take a brief moment to focus on the sentiment analysis we’re doing using the nltk python package. The sentiment analysis is using the VADER method, which is a sentiment analysis method.
It’s apparently best used for short blurbs, like tweets or in this case, iMessage texts. It also can handle slang and punctuation. In addition to being lightweight, these factors made it a good candidate for my project.
VADER stands for Valence Aware Dictionary for Sentiment Reasoning. It’s a model that can handle both positive and negative elements as well as indicates the level of intensity of those emotions.
Under the hood, it relies on a dictionary that maps lexical features to emotion intensities using sentiment scores. The sentiment score of a text can be obtained by summing up the intensity of each word.
It understands the emphasis of capital letters as well as differing punctuation.
In our code, I’m using the compound result to infer overall feeling. That means that if there are strongly positive elements and strongly negative elements, we might just say that the text itself is neutral.
Here are a couple examples using the model that I’m utilizing in code.
if __name__ == "__main__":
model = SentimentIntensityAnalyzer()
text = "This was a great movie"
scores = model.polarity_scores(text)
print(f"Text: {text} Scores: {scores}")
text = "This was a great movie!!"
scores = model.polarity_scores(text)
print(f"Text: {text} Scores: {scores}")
text = "This was a GREAT movie!!"
scores = model.polarity_scores(text)
print(f"Text: {text} Scores: {scores}")
text = "This was NOT a great movie"
scores = model.polarity_scores(text)
print(f"Text: {text} Scores: {scores}")
johnlarkin@Larkin-MacBook-Air 6:19:59$ python sentiment_classifier.py
Text: This was a great movie Scores: {'neg': 0.0, 'neu': 0.423, 'pos': 0.577, 'compound': 0.6249}
Text: This was a great movie!! Scores: {'neg': 0.0, 'neu': 0.39, 'pos': 0.61, 'compound': 0.6892}
Text: This was a GREAT movie!! Scores: {'neg': 0.0, 'neu': 0.356, 'pos': 0.644, 'compound': 0.7519}
Text: This was NOT a great movie Scores: {'neg': 0.452, 'neu': 0.548, 'pos': 0.0, 'compound': -0.5096}
Overall, it’s not super sophisticated, but for our use case, this seems acceptable.
Here’s another reference to some more information about the VADER method.
Enhanced Search
In this section, we’ll unpack the search sub-command.
You can either search by contact name or contact number. There’s a limit number that you can specify as well in case you don’t want to push all the messages to stdout.
Here’s the driving core part of the query (not pulling in contact information) for a lot of the search logic.
Driving Query
SELECT
datetime (message.date / 1000000000 + strftime ("%s", "2001-01-01"), "unixepoch", "localtime") AS message_date,
message.text,
message.is_from_me,
chat.chat_identifier
FROM
chat
JOIN chat_message_join ON chat. "ROWID" = chat_message_join.chat_id
JOIN message ON chat_message_join.message_id = message. "ROWID"
WHERE
message.text like '%{search_text}%'
ORDER BY
message_date ASC;
Examples
Here are a couple of examples of ways you can search. The results are quick (and given you’re searching across all of your message history ever) it seems more performant than normal iOS searching (and probably about the same as searching across your Mac).
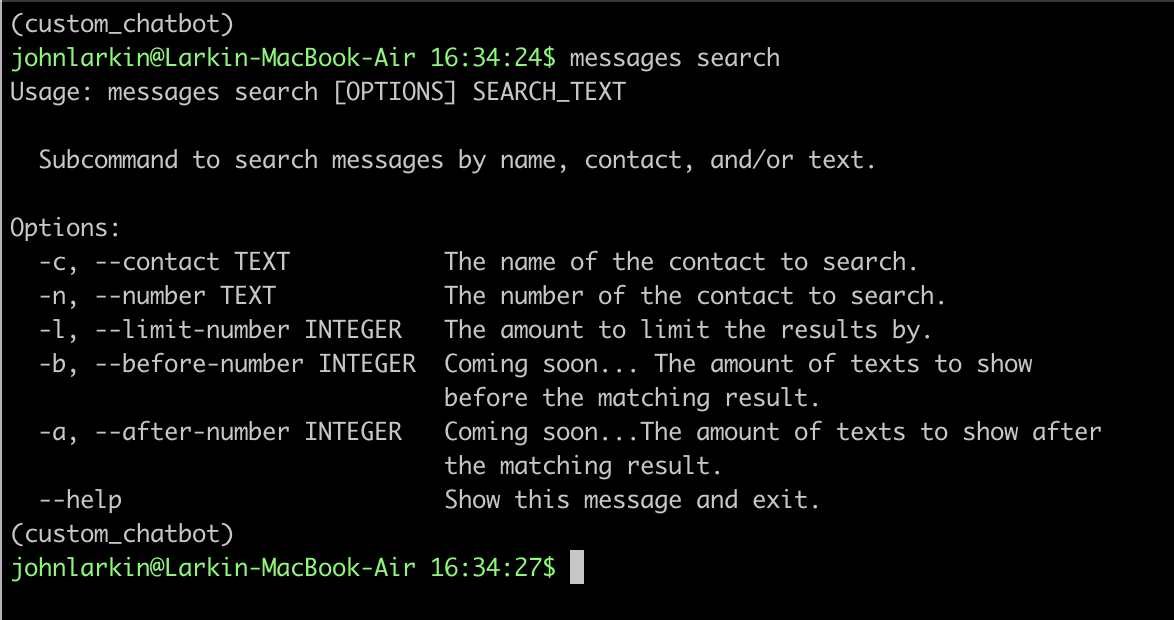
You can also see from the following example that we’ll reject the command if no search text is specified.
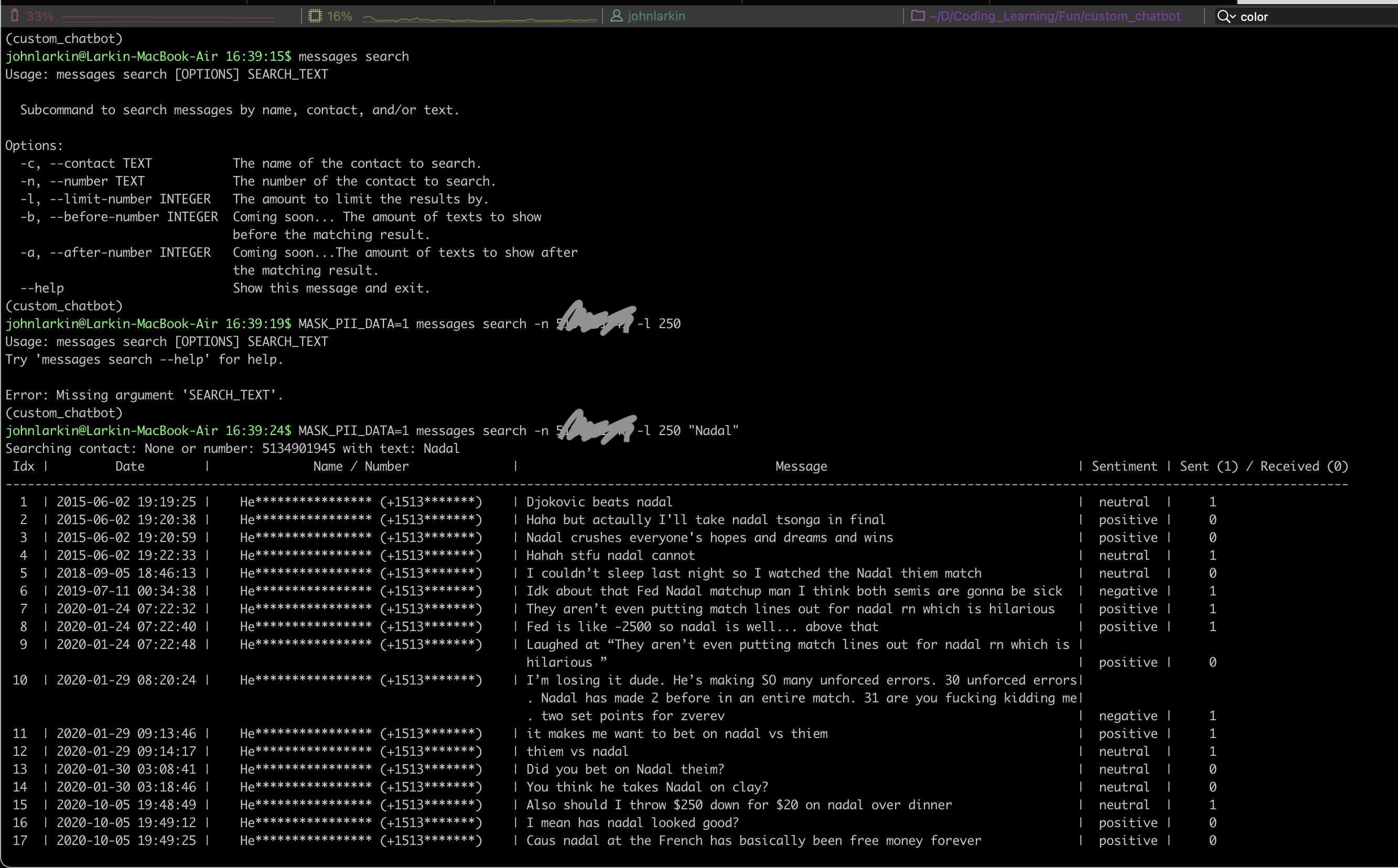
Here’s an example of masking the actual message text as well.
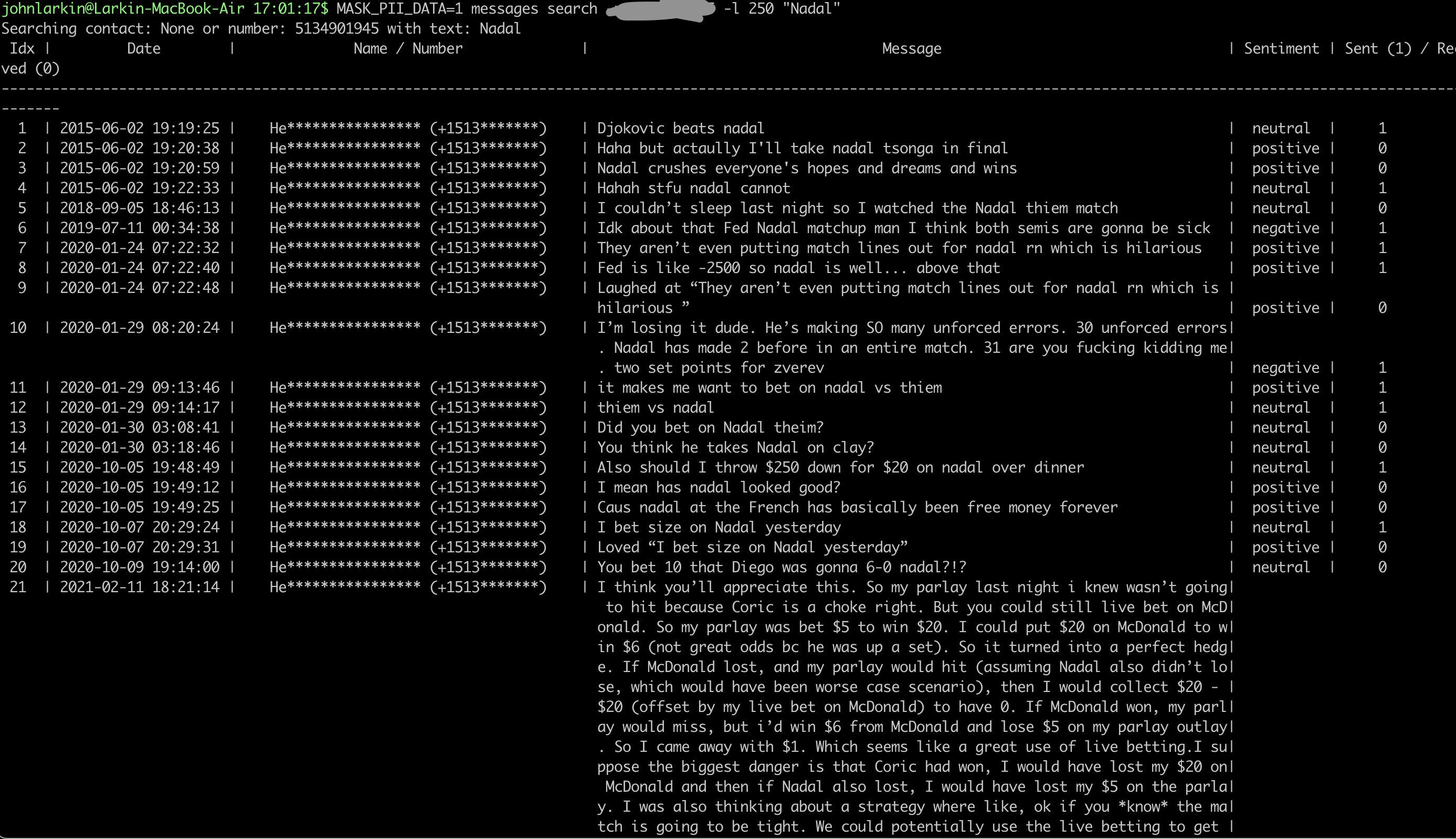
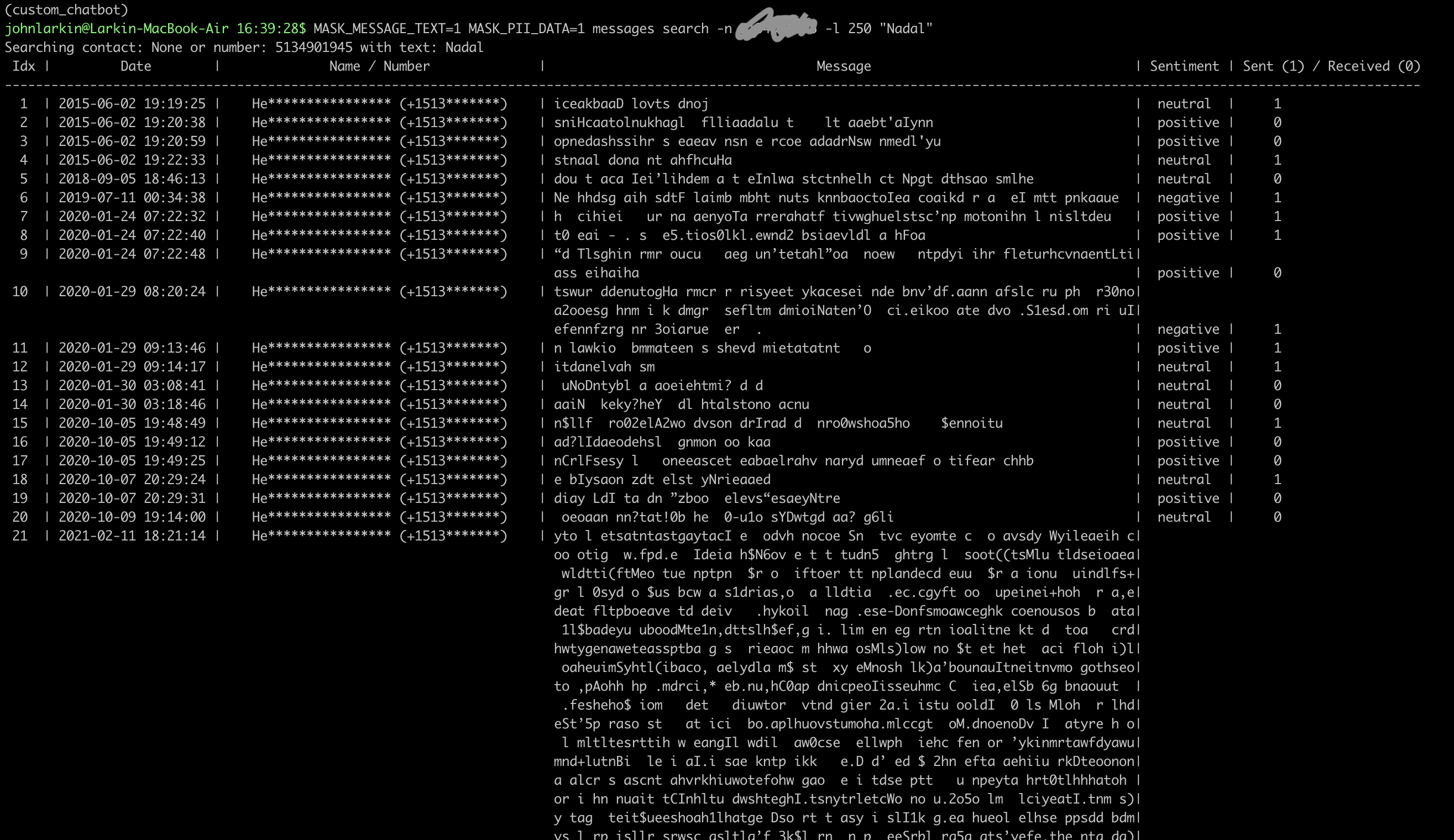
You can see a couple of nice things about this output - although definitely not the UI given that was not the focus of the project. We’re incorporating the Vader sentiment analysis result and analyzing if the text is positive or negative. We also are including who sent or received the message.
Performance
Again, it’d be worthwhile for me to do more extensive timing tests, but on first glance, it looks pretty good.
(custom_chatbot)
johnlarkin@Larkin-MacBook-Air 16:45:08$ time MASK_PII_DATA=1 messages search -n 513******* "Nadal"
0.14s user 0.03s system 96% cpu 0.183 total
That’s scanning over messages all the way back to 2015 and doing it in less than half a second. So… I’ll take that.
Message Dump
The get or message dump command is going to not require any search text, but going to have a similar output to the search command.
Again, the other nice feature with the get command is that you can dump all of the messages across all of your different contacts for a given date. (I didn’t choose to incorporate this feature into search because I thought it redundant to constrain a search space to an individual day).
Driving Query
SELECT
datetime (message.date / 1000000000 + strftime ("%s", "2001-01-01"), "unixepoch", "localtime") AS message_date,
message.text,
message.is_from_me,
chat.chat_identifier,
IFNULL(adb_record.ZFIRSTNAME, 'N/A') || ' ' || IFNULL(adb_record.ZLASTNAME, 'N/A')
FROM
chat
JOIN chat_message_join ON chat. "ROWID" = chat_message_join.chat_id
JOIN message ON chat_message_join.message_id = message. "ROWID"
LEFT JOIN adb.ZABCDPHONENUMBER adb_phone
ON chat.chat_identifier like '%' || replace(replace(replace(replace(adb_phone.ZFULLNUMBER, ' ', ''), '+', ''), ')', ''), '(', '')
LEFT JOIN adb.ZABCDRECORD adb_record
ON adb_phone.ZOWNER = adb_record.Z_PK
WHERE
chat.chat_identifier like '%{get_number}'
ORDER BY
message_date ASC;
Examples
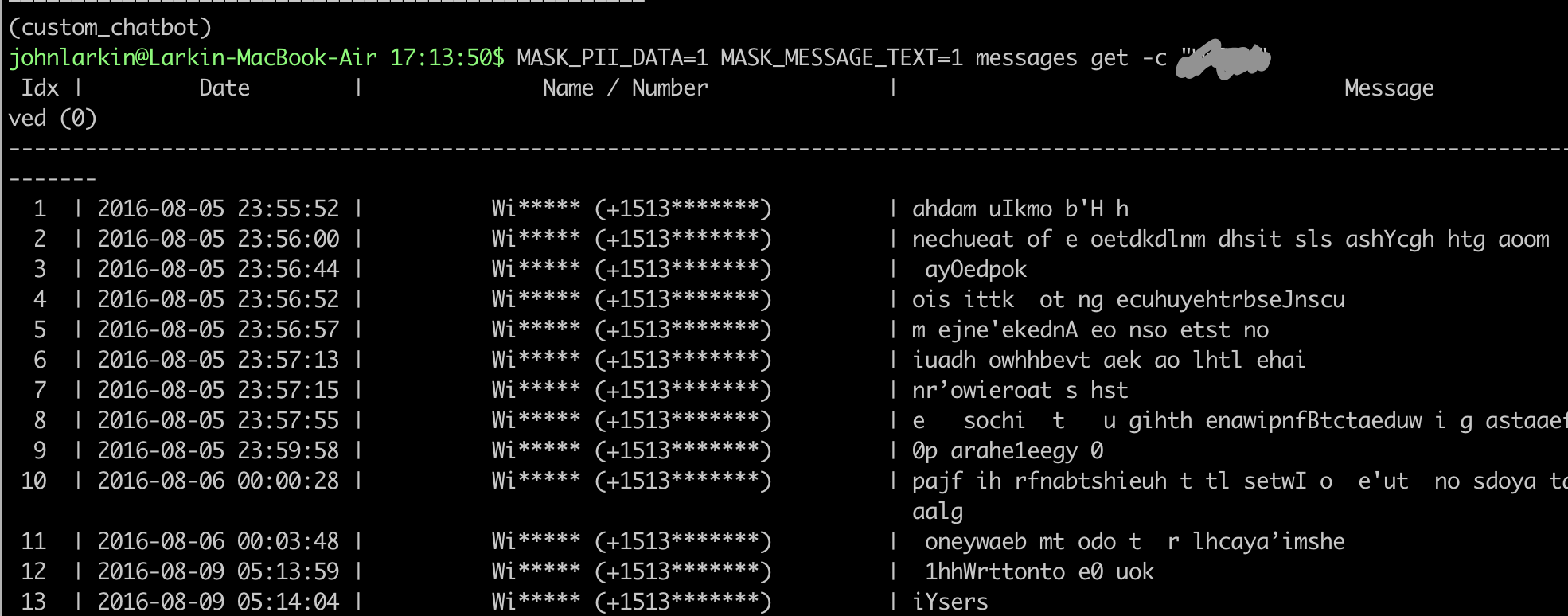
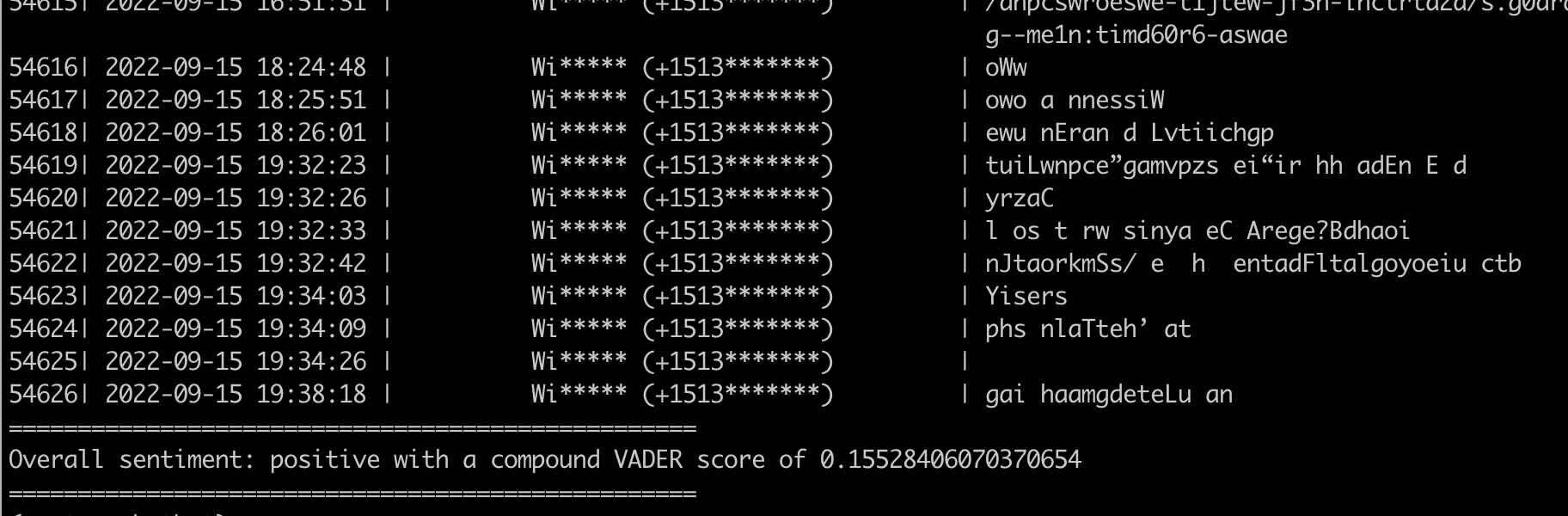
Performance
This one is a bit more juicy because we’ve got a lot of data. There are ~55k messages that we’re formatting, doing some light sentiment analysis on each text, aggregating those results, and writing to stdout as part of this query. So… it’s certainly not trivial.
Here’s a performance example.
(custom_chatbot)
johnlarkin@Larkin-MacBook-Air 17:26:44$ time MASK_PII_DATA=1 MASK_MESSAGE_TEXT=1 messages get -c "W****"
175.18s user 2.50s system 86% cpu 3:24.32 total
Light Trend Analysis
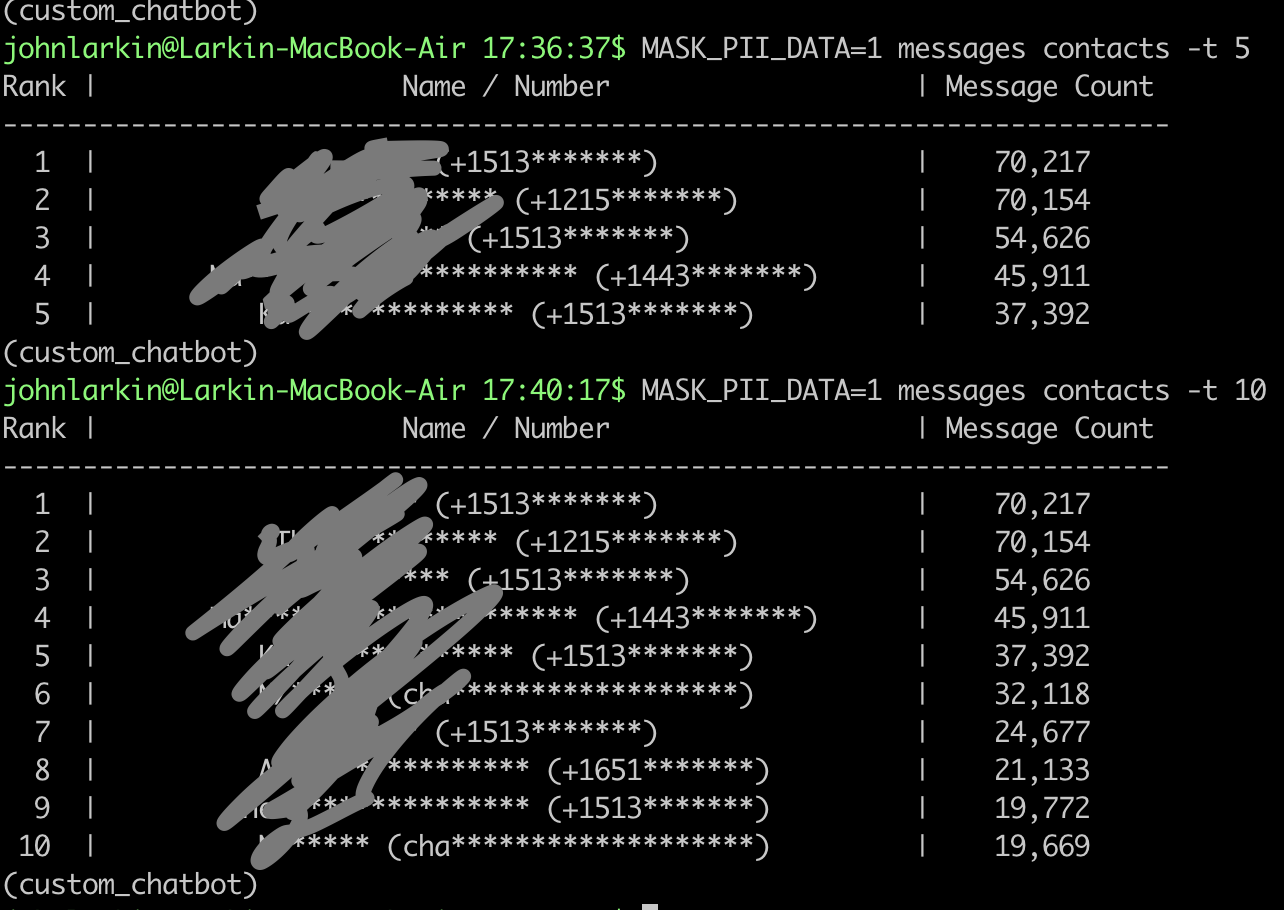
Most Texted Friends
Note, that this will not include contacts from which you’ve deleted the entire message history from (read: it might not include some of your exes).
Driving Query
SELECT
chat.chat_identifier,
count(chat.chat_identifier) AS message_count
FROM
chat
JOIN chat_message_join
ON chat.ROWID = chat_message_join.chat_id
JOIN message
ON chat_message_join.message_id = message.ROWID
GROUP BY
chat.chat_identifier
ORDER BY
message_count DESC;
Examples
Here are some example results. You’ll note that some of the most texted contacts match chat.* regex which means they’re just group chats that have a set unique id.
Performance
This will not be analyzed for this section.
Vader Results
Driving Query
I’m doing most of the analysis of te actual message text in Python, so there’s no real query to show here.
Examples
The examples from above should cover the analysis. We’re simply doing a running average in terms of the aggregate VADER score. Something similar to:
for message in results:
score = self.sentiment_model.analyze_message(message)
sum_compound_score += score.compound
aggregate_score = sum_compound_score / len(results)
Performance
This will not be analyzed for this section.
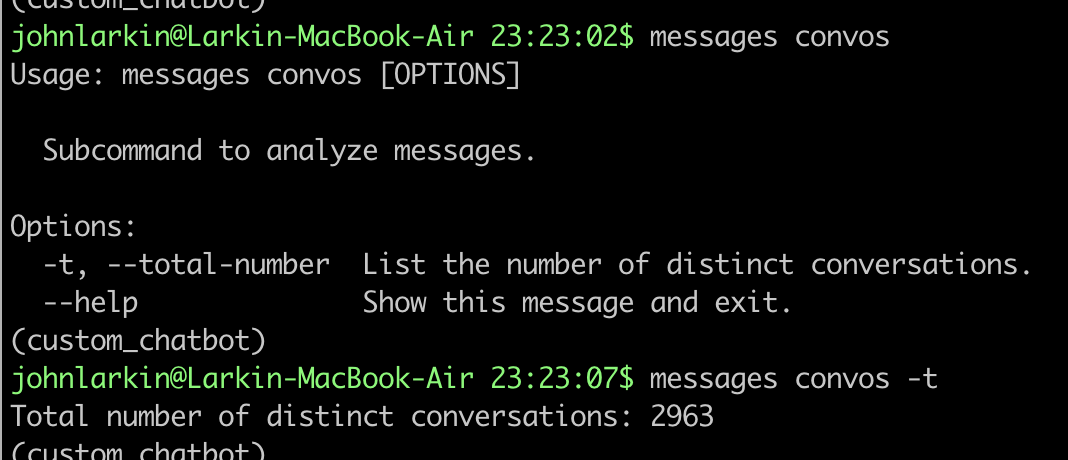
Total Number of Distinct Convos
This one is a simple one, so once again a Driving Query and Performance section will not be included.
Examples
Conclusion
This was another good exploration of some new technology that I wasn’t as familiar with.
- Infrastructure
- Compared to the Porvata project, this project really didn’t require many infrastructure tools. It was good exposure into
setuptoolswith Python- I hope to eventually push this to
pipso that people can quickly install if they so desire
- I hope to eventually push this to
- All of the code runs locally so there aren’t any server interactions
- Standard Python development tools
- Compared to the Porvata project, this project really didn’t require many infrastructure tools. It was good exposure into
- Software